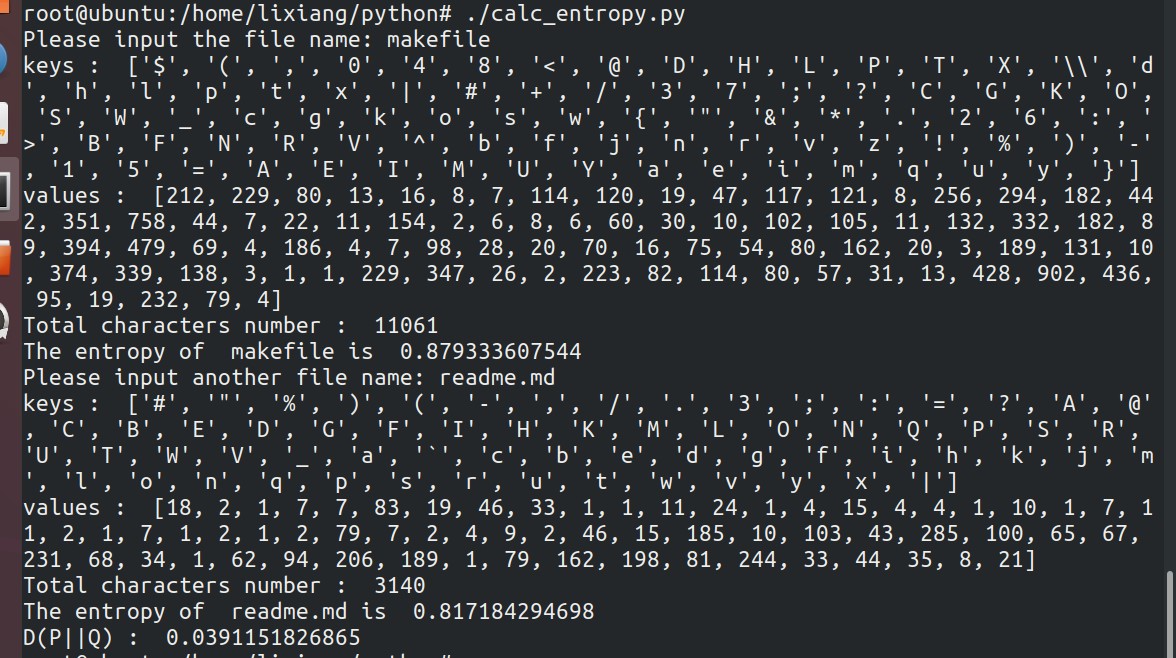
任意摘录一段文字,统计这段文字中所有字符的相对频率。假设这些相对频率就是这些字符的概率,请计算其分布的熵。按上述同样的方法计算字符分布的概率,然后计算两段文字中字符分布的 KL 距离。
考虑到汉字总数较多,英文单词也很多;需要大量的数据才有参考意义。所以只是对英文字符进行处理。程序中数据makefile和readme.md来自工作中项目的两个文本文件。真实情况中可能两段文字中所包含的字符不完全相同,所以程序中采用两段文字中共有的字符进行计算KL距离。
1 | #! /usr/bin/python |
程序运行结果: